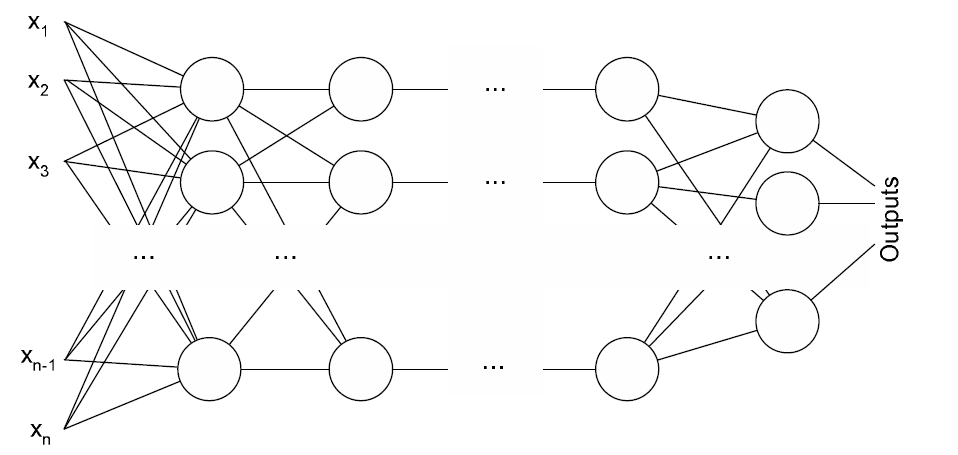
Архитектура многослойного перцептрона
Многослойный перцептрон Румельхарта — частный случай перцептрона Розенблатта в котором один алгоритм обратного распространения ошибки обучает все слои. К сожалению, название по историческим причинам не отражает особенности данного вида перцептрона, т.е. не связанно с тем, что в нем несколько слоев (так как, несколько слоев было и у перцептрона Розенблатта). Особенностью является наличие более чем одного обучаемого слоя (как правило два или три, для применения большего числа на данный момент нет обоснования, теряется скорость без приобретения качества). Необходимость в большом количестве обучаемых слоев отпадает, так как теоретически единственного скрытого слоя достаточно, чтобы перекодировать входное представление таким образом, чтобы получить линейную карту для выходного представления. Но есть предположение, что используя большее число слоев можно уменьшить число элементов в них, т.е. суммарное число элементов в слоях будет меньше, чем если использовать один скрытый слой.
Формирование понятия о многослойном перцептроне[]

В оригинале Минский показывает этим рисунком схему "о параллельном вычислении", при этом символами обозначены функции. Множество функций вычисляются параллельно от n переменных, которые обозначенны на рисунке каждой точкой. Поэтому термин однослойный перцептрон здесь совершенно не уместен.


{kind=link}
{kind=link}
В 1986 году Румельхарт пишет книгу [1], где обосновывает необходимость алгоритма обратного распространения. Но с первых же строк происходит серьезное заблуждение Румельхард приводит рисунок из книги Минского и подписывает его совершенно произвольно - "Однослойный перцептрон, анализируемый Минским и Папертом". А это совершенно не верно, Минский и Паперт никогда не анализировали однослойный перцептрон, они анализировали именно перцептрон Розенблатта, который собственно и изображен на рисунке - и он является трехслойным. И это была бы только терминологическая неточность, если бы не дальнейшие выводы Румельхарда (а не Минского, как это можно было бы подумать).
In their famous book Perceptrons, Minsky and Papert (1969) document the limitations of the perceptron. The simplest example of a function that cannot be computed by the perceptron is the exclusive-or (XOR). [В их известной книге Perceptrons, Минский и Паперт (1969) документируют ограничения перцептрона. Самым простым примером функции, которая не может быть вычислена перцептроном, является исключающие - или (XOR).]
Причем здесь были Минский и Паперт, совершенно не понятно, т.к. на протяжении всей своей книги они ни разу не говорили о функции XOR. Ни говоря, уже о том, что это явно не соответствует истине - перцептрон Розенблатта легко решает проблему XOR. Такое представление действительно можно получить, если убрать из перцептрона один слой, что собственно ошибочно и было сделанно Румельхардом. Отсюда и появилось название "однослойный перцептрон", которое потом стало основой целой плияды недоразумений.
Далее, Румельхард совершенно обоснованно пишет:
Thus, we see that the XOR is not solvable in two dimensions, but if we add the appropriate third dimension, that is, the appropriate new feature, the problem is solvable. Moreover, as indicated in Figure 4, if you allow a multilayered perceptron, it is possible to take the original two-dimensional problem and convert it into the appropriate three-dimensional problem so it can be solved. Indeed, as Minsky and Papert knew, it is always possible to convert any unsolvable problem into a solvable one in a multilayer perceptron. In the more general case of multilayer networks, we categorize units into three classes: input units, which receive the input patterns directly; output units, which have associated teaching or target inputs; and hidden units, which neither receive inputs directly nor are given direct feedback. This is the stock of units from which new features and new internal representations can be created. The problem is to know which new features are required to solve the problem at hand. In short, we must be able to learn intermediate layers. The question is, how? The original perceptron learning procedure does not apply to more than one layer. Minsky and Papert believed that no such general procedure could be found. To examine how such a procedure can be developed it is useful to consider the other major one-layer learning system of the 1950s and early 1960s, namely, the leastmean-
square (LMS) learning procedure of Widrow and Hoff (1960).
Таким образом, мы видим, что XOR не разрешим в двух измерениях, но если мы добавляем соответствующее третье измерение, то есть, соответствующую новую особенность, проблема разрешима. Кроме того, если Вы позволяете многослойный перцептрон, возможно взять оригинальную двумерную проблему и преобразовать это в соответствующую трехмерную проблему, таким образом это может быть решено. Действительно, Минский и Паперт знали, что всегда возможно преобразовать любую неразрешимую проблему в разрешимый в многослойном перцептроне. В более общем случае многослойных сетей мы категоризируем единицы в три класса: входные единицы, которые получают входные образцы непосредственно; единицы продукции, которые связали обучение или предназначаются для входов; и скрытые единицы, которые не получают входы непосредственно, ни даны прямую обратную связь. Это - запас единиц, от которых могут быть созданы новые особенности и новые внутренние представления. Проблема состоит в том, чтобы знать, какие новые особенности обязаны решать проблему. Короче говоря, мы должны быть в состоянии изучить промежуточные слои. Вопрос, как? Оригинальный перцептрон обучение процедуры не относится к больше чем одному слою. Минский и Паперт полагали, что никакая такая общая процедура не может быть найдена. Чтобы исследовать, как такая процедура может быть развита, полезно рассмотреть другую главную систему изучения одного слоя 1950-ых и в начале 1960-ых, а именно, leastmean - квадрат (LMS) изучение процедуры Widrow и Hoff (1960).
Но пишет это таким образом, как будто все это не относится к перцептрону Розенблатта. Под словами многослойный перцептрон оказывается ровно то, что понимается под перцептроном Розенблаттом, а именно : "три класса: входные единицы, которые получают входные образцы непосредственно; единицы продукции, которые связали обучение или предназначаются для входов; и скрытые единицы, которые не получают входы непосредственно". Другое дело, что действительно "Оригинальный перцептрон обучение процедуры не относится к больше чем одному слою.", но в этом и небыло необходимости, т.к. первый слой выбирался случайным образом, что строго математически позволяло "взять оригинальную двумерную проблему и преобразовать это в соответствующую трехмерную проблему". Кроме того, Розенблаттом рассматривался полный аналог многослойного перцептрона Румельхарда, под названием перцептрон с переменными S-A связями, где помимо прочего было доказано, что процедура обучения аналогичная обратному распространению ошибки невсегда может гарантировать достижение решения (обеспечить сходимость).
Но в результате эти недопонимания Румельхардом, тем ни менее привели его к созданию алгоритма обратного распространения ошибки, хотя сам метод был описан ранее [2]. Но как писал Уоссермен [3] :
Хотя подобное дублирование является обычным явлением для каждой научной области, в искусственных нейронных сетях положение с этим намного серьезнее из-за пограничного характера самого предмета исследования. Исследования по нейронным сетям публикуются в столь различных книгах и журналах, что даже самому квалифицированному исследователю требуются значительные усилия, чтобы быть осведомленным о всех важных работах в этой области.
Отличия многослойного перцептрона от перцептрона Розенблатта[]
- Использование нелинейной функции активации, как правило сигмоидальной.
- Число обучаемых слоев больше одного. На практике не более трех.
- Сигналы поступающие на вход, и получаемые с выхода не бинарные, а могут кодироваться десятичными числами, которые нужно нормализовать, так чтобы значения были на отрезке от 0 до 1 (нормализация необходима как минимум для выходных данных, в соответствии с функцией активации - сигмоидой).
- Допускается произвольная архитектура связей (в том числе, и полносвязные сети).
- Ошибка сети вычисляется не как число неправильных образов после иттерации обучения, а как некоторая статистическая мера невязки между нужным и получаемым значением.
- Обучение проводится не до отсутствия ошибок после обучения, а до стабилизации весовых коэффициентов при обучении или прерывается ранее, чтобы избежать переобучения.
Многослойный перцептрон будет обладать функциональными преимуществами по сравнению с перцептроном Розенблатта только в том случае, если в ответ на стимулы не просто будет выполнена какая-то реакция (поскольку уже в перцептроне может быть получена реакция любого типа), а выразится в повышении эффективности выработки таких реакций. Например, улучшится способность к обобщению, т.е. к правильным реакциям на стимулы которым перцептрон не обучался. Но на данный момент таких обобщающих теорем нет, существует лишь масса исследований различных стандартизированных тестов, на которых сравниваются различные архитектуры.
Примечания[]
- ↑ Parallel Distributed Processing: Explorations in the Microstructures of Cognition / Ed. by Rumelhart D. E. and McClelland J. L.— Cambridge, MA: MIT Press, 1986.
- ↑ Werbos P. J. 1974. Beyond regression: New tools for prediction and analysis in the behavioral sciences. Masters thesis, Harward University
- ↑ Уоссермен, Ф. Нейрокомпьютерная техника: Теория и практика = Neural Computing. Theory and Practice. — М.: Мир, 1992. — 240 с.
См. также[]
Литература[]
- Ф. Вассерман Нейрокомпьютерная техника: Теория и практика. — М.: «Мир», 1992.
- Саймон Хайкин Нейронные сети: полный курс = Neural Networks: A Comprehensive Foundation. — 2-е изд. — М.: «Вильямс», 2006. — С. 1104. — ISBN 0-13-273350-1
Внешние ссылки[]
- Книга Kevin Swingler «Applying Neural Networks. A practical Guide» (перевод Ю. П. Маслобоева)
- Миркес Е. М., Нейроинформатика: Учеб. пособие для студентов с программами для выполнения лабораторных работ. Содержит лекции и программное обеспечение, в том числе — для моделирования многослойных перцептронов
- Сайт Виктора Царегородцева, содержащий научные статьи по применению многослойного перцептрона
Это основополагающая версия, написанная участниками этого проекта. Но содержимое этой страницы очень близкое по содержанию предоставлено для раздела Википедии на русском языке. Так же, как и в этом проекте, текст этой статьи, размещённый в Википедии, доступен на условиях CC-BY-SA . Статью, размещенную в Википедии можно найти по адресу: Многослойный перцептрон Румельхарта.